【入門用】Algolia の概念的知識のまとめ
こんにちは。Firebase を使ってるプロジェクトで「検索機能を作っておいてくれ」となって、定番の Algolia を導入するになった Nash です。
この記事は「Algolia の中で使われる概念や用語の説明・まとめた記事」です。基本的には、Algolia の公式ドキュメントを読めばわかることです。ただ、独自の単語が出てくることが多いので、その整理となります。
また、API の詳細・使い方については、この記事では取り扱いません。概要説明くらいです。
基礎知識
Algolia とは?
全文検索を提供する Saas です。
たとえば、Firestore では SQL ライクなクエリを発行してデータを操作ができます。ですが、検索を実現するためのクエリ・API が容易されていません。(やろうと思えば力技で出来ますが・・・)
そのため、Firebase の公式としても、検索を実現したい場合は Algolia を併用する旨が記述されてます。
検索を行うデータは?
Algolia の中で JSON 形式でデータを保持しておき、その中で検索を行います。
アプリケーションの各種データは RDS や Firesotre などで管理されていると思います。ですが、更に検索用に Algolia にもデータを入れないといけません。つまりデータを重複して管理することになります。
データの扱いはキャッシュと同じように扱うのがベターです。つまり、RDS などのデータを主とします。主のデータに対して CREATE/UPDATE/DELETE が行われたら、Algolia 側にもその命令を発行する形です。
RDS と対応した用語
RDB における、テーブル・レコード・カラムが Algolia だと微妙に違う言葉を使ったりします。
| RDB | Algolia | MEMO |
|---|---|---|
| Table | Index | 複数形は indicies。レコードの集合体 |
| Record | Record | Attribute の集合体 |
| Column | Attribute | key/value ペア。値の集合体。 |
Algolia を使うときは、これを丸暗記したほうが良いです。
Algolia の検索までの流れ
検索機能を使うまでは、大きく分けて3つのフローに別れます。
-
①DataSync = Algolia にデータを突っ込む。
-
②Ranking = Algolia 内部でインデックスを作成してくれる。
-
③Fetch = 検索をかけると理想的な結果が表示される。
② は Algolia 側で行ってくれるので、Developer が行うのは ①/③ のみなので直感的ですね。
(② は、Index-timeとか、とも書かれてる)
提供されている API
2 種類。普通の API かコンポーネントです。普通の API では、PHP や Ruby などから呼び出して実行します。
もう1つは、コンポーネント(InstantSearch Widgets)にです。
React・Vue・Angular 用にコンポーネント単位で機能が用意されています。なので、簡単な検索ボックスは、これを導入するだけで完了です。ただ、デザインの制約やロジックなどが複雑な機能だった場合は、オレオレコンポーネントを作ったほうがベターです。
用語知識
Synonyms
同義異音を定義する。アプリのビジネスドメインによって発生するであろうものをユーザーが定義できる。PC =パソコン、みたいなもの。
(Algolia 特有ではなくて、普通に英単語ですね)
Ranking formula
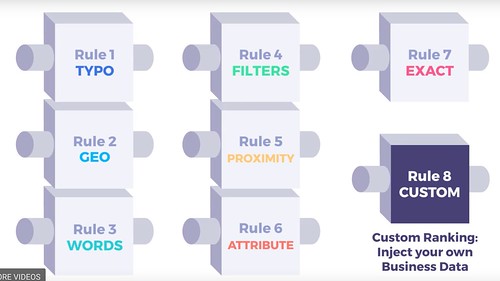
検索結果にて、どの順番で表示させるか?の計算アルゴリズム。 Algolia はあいまい検索なので、順番が肝です。
具体的には、「tie-breaking アルゴリズム」→「ソート」→「ranking-criteria(8 つのルール)」の優先度で、表示する内容・順番を決めてます。
ちなみに、custom-ranking を設定していると、RankingCriteria の 8 つ目のルールとしてソートが行われる。
▼ RankingCriteria
プラクティス
ここでは、各種プラクティスをまとめました。これも公式 DOC に乗っているものもあれば、自分が調べた MEMO 的なのもあります。
データサイズはできる限り小さくする
検索用・表示用・ソート用、だけに絞って、それ以外のデータは保存しない。が公式提供のプラクティスです。
仮に Attribute が増える場合は、既存の Record に対しても Attribute を更新すれば良いだけです。
Index 設計について
複数企業が使う想定のサービスだったので、Index をどうするかなー?というわけで Index 設計を色々考えてみました。
結論、マルチテナントであっても1つの Index に全企業のデータを入れて、fetch するときに filter して取得するのが一番良さそうです。
この選択の懸念として、Filter 条件をミスったりで事故ると、他の企業の情報が見れてしまう危うさがあります。
他のやり方として、企業毎に Index を切り分ける方法もあります。こちらはセキュリティ的な危うさがなくなりますが、マイグレーションがとんでもなく辛くなります。仮に登録企業数が 1000 とかになると、マイグレーションがその分実行されるわけです。
考え方はこちらの記事を参考にしました。
▷つらくないマルチテナンシーを求めて: 全て見せます! SmartHR データベース移行プロジェクトの裏側 - builderscon tokyo 2018
▷“Best practices with how to structure an index - Open Q&A - Algolia Community”
この件は Algolia、というよりもマルチテナント系のシステムについてのプラクティスですね。
各種設計などで迷ったら
困ったらここで検索するとたいていのことは探せられる。特に設計については先に調べたり、考慮してから行うべきかと。
おわりに
Algolia については知っていたのですが、自分が実装するタイミングが初めてだったのと、周りに有識者が誰もいなかったので概念的なところをまとめてみました。
Algolia に記事はどれもハンズオンが多くて、自分も動けば OK な感じで進めようかなー、とも思ったのですが、気になったので調べてみました。
この記事が誰かの助けになれば幸いです。